Introduction to Beetlebox CI Concepts
This document will give a brief summary of the concepts used by BeetleboxCI.
Overview
BeetleboxCI is aimed to make continuous integration seamless and simple for engineering designs in the FPGA, ASIC and IOT space. CI flows have many associated concepts that are designed to be re-usable. The following image shows the basic concepts of BeetleboxCI:
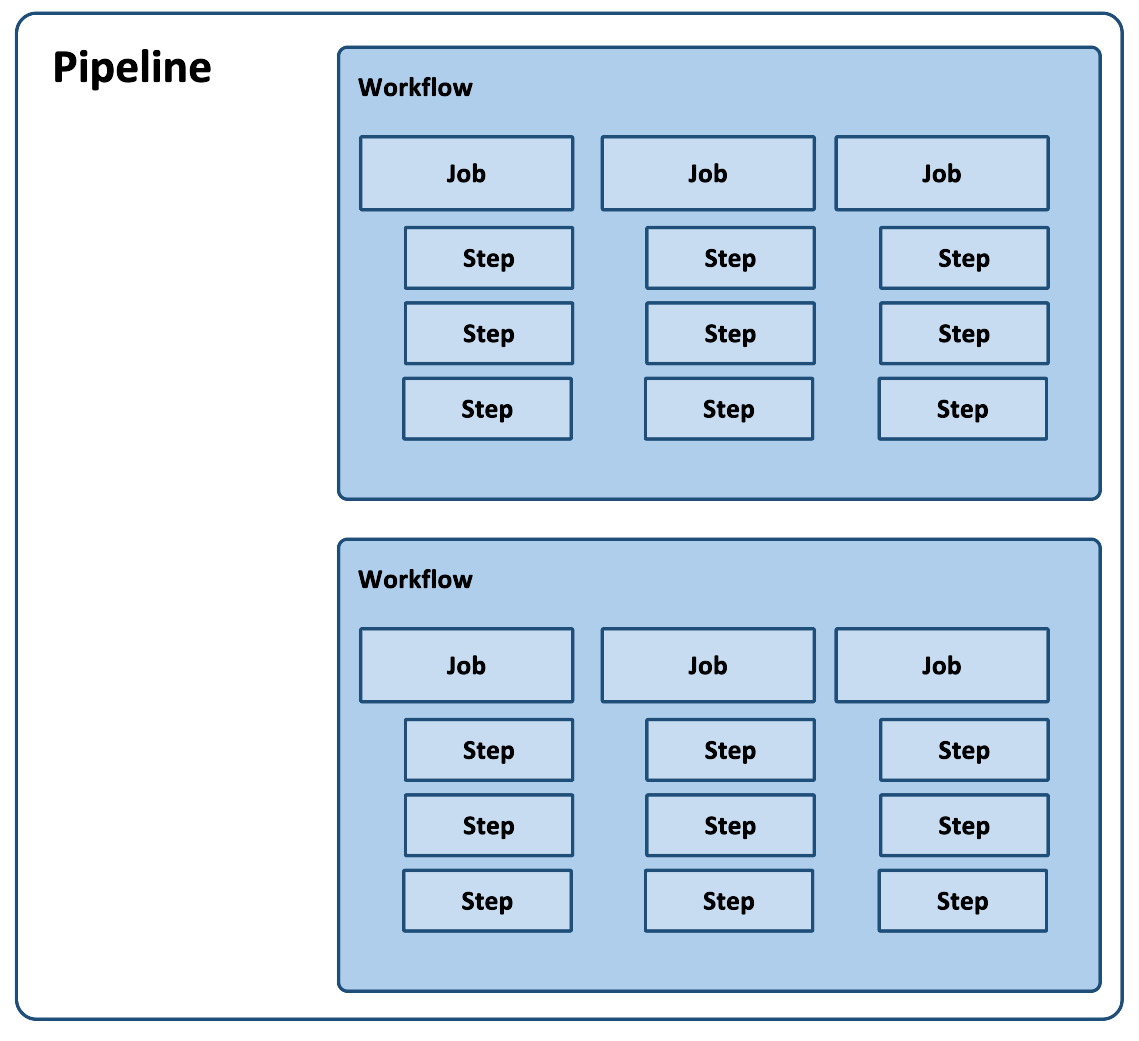
Artifacts
Artifacts are files that have been generated by a job and is kept after the workflow has completed. These files are used for long-term storage and help provide a single file source for all your team. Artifacts may also be uploaded for use in jobs. For example, board files may be uploaded to build for that particular builds.
For more information on artifacts and the artifact store, please see the following document.
Concurrency
Jobs that are independent of each other are able to run concurrently by default. BeetleboxCI does not enforce an upper limit on the number of containers that can be running simultaneously. If independent jobs are being queued, that is usually due to a lack of resources available on the (virtual) machine. Once running jobs complete and free up resources on the machine, then the queued jobs can resume.
Configuration files
BeetleboxCI follows configuration-as-code principles.
This means that the entire pipeline in the project may be described in a configuration file that is placed at the root of your git repository in .bbx/config.yaml.
This allows the configuration to be versioned and changed just as an other part of the git repository.
+-- Project files
+-- .bbx
| +-- config.yaml
Full details of the configuration file YAML can be found in the BeetleboxCI YAML configuration document.
Current Working directory
The current working directory is the location inside a container where a job will be executed.
By default, the current working directory is set to ~/, but the user may specify a different location in their .bbx/config.yaml file.
Dependencies
For some jobs to run, it is necessary that another job completes first. Then we say that one job depends on another job. In such cases, the dependent job will be queued until its prerequisite job(s) complete. Such jobs will therefore run sequentially rather than concurrently. If a job fails, then any job that depends on it will also fail.
Devices
Device support is the key feature of BeetleboxCI that differentiates it from other CI/CD platforms. Devices are external hardware that are independent of the server/cluster running BeetleboxCI. BeetleboxCI has specialised functionality to communicate with external devices and information about these devices are stored in a device registry, which is part of the BeetleboxCI application. Examples of such devices are FPGAs and embedded systems. BeetleboxCI has the functionality to build and deploy applications onto such external devices. The user can specify commands to communicate with the devices in configuration files. This includes transferring files/data to/from devices as well as directly running commands on devices.
Images
An image is a compressed package that contains the settings and a file system to orchestrate a container.
A container is a clean execution environment that is used to run the commands for the job.
BeetleboxCI provides an image registry to store images locally, which can save bandwidth in the instance of having to pull large images from remote registries for repeat CI runs.
BeetleboxCI still supports the use of images that are stored in remote, public registries such as Dockerhub.
The user declares the image to use for a job in the .bbx/config.yaml file.
For more information on images and the image registry, please see the following document.
Jobs
Jobs are a distinct set of steps that are to be run as part of the pipeline.
They are also used to specify the runner that will be used to execute these tasks.
Each job is defined in the .bbx/config.yaml file for each pipeline.
For more information on jobs, please see the following document.
Nodes
A node is a (physical or virtual) machine that is in the cluster (BeetleboxCI is built on Kubernetes) Nodes in a cluster can have certain roles. e.g. Control plane / master (same thing), or a worker node. Worker nodes merely run jobs, while control plane and master nodes run system processes and they can also optionally run jobs. The current version of BeetleboxCI does not support multiple nodes, but this is a feature that will be added in a future release.
Pipelines
A pipeline is the complete collection of automated processes that are to be executed when a run is triggered. Each project will have a single pipeline but the pipeline may have many branches according to the version control system where its codebase is stored. When a project is triggered to run, it will pull code from the git repository and configure a pipeline through the configuration file.
Resource specification
When defining jobs in a configuration file, the user may specify the amount of resources (CPU and RAM) that are allocated to a particular job.
If the resource_spec for a job is not defined, BeetleboxCI will assign a default value of small to it.
Therefore, we strongly recommend that resource specification is manually defined instead of using the default value that BeetleboxCI assigns.
jobs:
build-vec:
resource_spec: medium
runner: local-runner
| Resource specification | CPU | RAM |
|---|---|---|
| micro | 0.5 | 2GiB |
| small | 1.0 | 4GiB |
| medium | 2.0 | 8GiB |
| large | 4.0 | 16GiB |
| xlarge | 8.0 | 32GiB |
| 1.5xlarge | 12.0 | 48GiB |
| 2xlarge | 16.0 | 64GiB |
Steps
A step is a single task to be performed. Typically, these tend to be a series of executable commands running in a shell, such as bash.
Triggers
Triggers are what causes a workflow to begin running. BeetleboxCI supports a number of different triggers. For example, when code is committed to the version control repository, a message is sent to BeetleboxCI that a code change has occured. This message acts as a trigger for BeetleboxCI to begin the automated processes in the pipeline.
User permissions
There are 3 types of user accounts on the BeetleboxCI platform:
- User - Can create pipelines and run jobs
- Admin - Can do the above as well as create/delete users
- Admin (Root) - Can do the the above as well as access the admin control panel of the webapp
Workflows
Workflows are used to organise jobs into a distinct run order.
One more more workflows together will form a pipeline and there may be multiple version control branches (for example a main branch and a develop branch).
A pipeline consists of multiple workflows that define the entire build and test process.
Individual workflows are defined in the .bbx/config.yaml file.
For more information on workflows, please see the following document